
Nadat besluitvormers overtuigd zijn om werk te maken van HR-analytics volgt vaak de vraag hoe HR-analytics geoperationaliseerd kan worden. Deze vraag is een meerkoppig monster. Een solide HR-analytics functie bestaat namelijk uit communicerende vaten en dus is het belangrijk om een goed antwoord te formuleren op alle vaten én te zorgen voor balans tussen de vaten. Er moeten dus vragen beantwoord worden als:
- Waar hangen we de HR-analytics functie op?
- Welke rollen nemen plaats in het HR-analytics team? Of bij kleinere organisaties: over welke eigenschappen moet onze HR-analytics man of vrouw beschikken?
- Welke tooling gaan we gebruiken voor data opslag, onderzoek, analyse, visualisatie?
- Hoe kun je oorzakelijke en voorspellende HR-analytics methodisch het beste aanpakken?
Drie methoden
Over het laatste punt – hoe kun je oorzakelijke en voorspellende HR Analytics het beste aanpakken? – is echter minder geschreven, terwijl ook dit bij uitstek een cruciaal onderdeel is om succesvol te worden.
Grofweg zijn er drie methoden te onderscheiden:
- Ongestructureerd data mining
- Hypothese gedreven data mining
- Gestructureerd data mining
De eerste methode kan het beste gekenmerkt worden door het woord ‘grasduinen’. In dit geval gaat een analist aan de slag met een dataset die bestaat uit alle variabelen waar hij/zij de hand op heeft kunnen leggen met als doel om verbanden te ontdekken, zonder vooraf enige sturing te krijgen. In theorie zou je hiermee baanbrekende inzichten kunnen ontwikkelen, doordat er geen enkele variabele wordt uitgesloten. In praktijk kost het veel tijd en dus geld én is de kans op succes lastig in te schatten. Niet ideaal dus als je de meerwaarde van iets nieuws aan wil tonen.
De tweede methode wordt veelal gebruikt door PHD-ers die zijn overgestapt naar het bedrijfsleven. Zij stellen een model op, op basis van hypothesen, zoeken de variabelen bij elkaar die in het model terugkomen en gaan met deze dataset aan de slag, zie voorbeeld deze figuur:
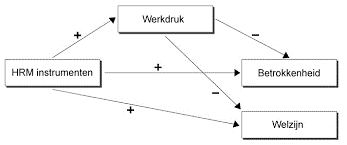
Het doel is om het model te bevestigen of te ontkrachten. Voordeel van deze methode is dat het een stuk gerichter is dan grasduinen. Nadeel is dat variabelen die niet in het model passen worden uitgesloten. Het gebeurt dus niet zelden dat er een onvolledige set aan inzichten wordt opgeleverd. Een onvolledige set aan inzichten heeft vervolgens tot gevolg dat de kans of uitdaging die speelt alsnog niet wordt benut/overwonnen doordat er iets over het hoofd is gezien.
Gestructureerd data minen
Een derde aanpak is om gestructureerd te data minen. In dit geval start de analist met het ophalen van de businessvraag om die vervolgens om te zetten in analysevragen. Voorbeeld:
Businessvraag voorbeeld: hoe kunnen we de omzet van onze winkels verhogen?
Analysevragen voorbeeld: wat is de optimale teamsamenstelling voor de winkels? Wat zijn de unieke kenmerken die een goed presterend team anders maken dan minder presterende teams?
Zodra er analysevragen zijn, wordt er een zo breed mogelijke dataset gecreëerd. Hierop gaat men binnen deze brede dataset op zoek naar interessante inzichten die in relatie staan tot de analysevragen. Het grote voordeel van deze methode is dat er doelgericht wordt gewerkt, wat tijd bespaart, terwijl er ook buiten de (te) sterk vereenvoudigde wereld van een hypothetisch model wordt gekeken.
Overigens is het wel leuk om binnen de gestructureerde data mine-methode wat tijd vrij te maken om mensen te laten aangeven welke uitkomsten ze verwachten om vervolgens op enig moment de aannames van mensen naast de uitkomsten van de analyse te leggen. Het is ons al vaak gelukt om HR-mythes te doorbreken.


In deze live online masterclass van een halve dag leer je hoe je een dossier opbouwt en een specifiek verbeterplan opstelt bij disfunctioneren van een medewerker. Inclusief wettelijk kader ontslagbeoordeling



